果然还是自己熟悉的东西写起来比较轻松,回头看看,数据类型我已经完成了大部分内容的介绍,还剩下数组、函数以及ES 6新加入进来的几种而已了。
那么我们先从函数(Function)开始:
1 概念
函数是一段可以反复调用的代码块。函数还能接受输入的参数,不同的参数会返回不同的值,如下例:
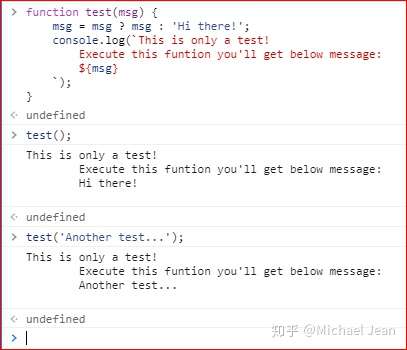
简单说明:上例当中声明了一个名为test的函数,仅接受一个或者零个参数,最终根据参数的不同在控制台生成不同结果的字符串。
2 声明函数
2.1 声明方式
JavaScript 有三种声明函数(Function Declaration)的方法,包括有:
- function命令
在本文开始的那个例子,就可以明确的看到function命令的使用方法:
function命令后面是函数名,函数名后面是一对圆括号,里面是传入函数的参数;函数体放在大括号里面——该命令所声明的代码区块,就是一个函数,下面又是一个简单的例子:

声明之后,通过函数名(参数)的形式就可以调用该函数了,如上例中使用print('test')调用。
这是最常用的声明方式。
- 函数表达式
按照基础的变量声明并赋值的方式,也可以声明一个函数,如:
这种写法将一个匿名函数赋值给变量。这时,这个匿名函数又称函数表达式(Function Expression),因为赋值语句的等号右侧只能放表达式。
采用函数表达式声明函数时,function命令后面不带有函数名。如果加上函数名,该函数名只在函数体内部有效,在函数体外部无效:

上面代码在函数表达式中,加入了函数名x。这个x只在函数体内部可用,指代函数表达式本身,其他地方都不可用。这种写法的用处有两个,一是可以在函数体内部调用自身,二是方便除错(除错工具显示函数调用栈时,将显示函数名,而不再显示这里是一个匿名函数)。因此,下面的形式声明函数也非常常见。
var f = function f() {};
需要注意的是,函数的表达式需要在语句的结尾加上分号,表示语句结束。而函数的声明在结尾的大括号后面不用加分号。总的来说,这两种声明函数的方式,差别很细微,可以近似认为是等价的。
- Function构造函数
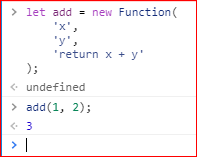
上面代码中,Function构造函数接受三个参数,除了最后一个参数是add函数的“函数体”,其他参数都是add函数的参数。
可以传递任意数量的参数给Function构造函数,只有最后一个参数会被当做函数体,如果只有一个参数,该参数就是函数体。
有个需要注意的地方是,即使不使用new命令,直接使用如下格式,其结果也是一样的:
let x = Function(
//...
);
不过,这种声明函数的方式非常不直观,几乎无人使用。
2.2 圆括号、return语句和递归
调用函数时,要使用圆括号运算符。圆括号之中,可以加入函数的参数。
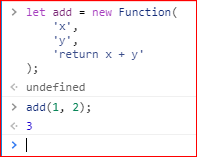
上面代码中,函数名后面紧跟一对圆括号,就会调用这个函数。
函数体内部的return语句,表示返回。JavaScript 引擎遇到return语句,就直接返回return后面的那个表达式的值,后面即使还有语句,也不会得到执行。也就是说,return语句所带的那个表达式,就是函数的返回值。return语句不是必需的,如果没有的话,该函数就不返回任何值,或者说返回undefined。
函数可以调用自身,这就是递归(recursion)。下面就是通过递归,计算斐波那契数列的代码。
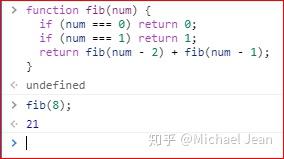
上面代码中,fib函数内部又调用了fib,计算得到斐波那契数列的第8个元素是21。
2.3 函数名提升
由于函数本身也是一种数据类型,所以JavaScript将函数名同样视为变量名,采用function命令声明函数时,整个函数会像变量声明一样,被提升到代码头部。所以,下面的代码不会报错,且可以正常执行:
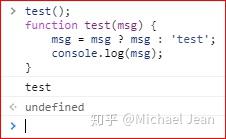
表面上test函数在声明之前已经执行了,但由于变量提升的原因,声明test函数的语句被提升到了最前面优先完成,故此在执行之前已经声明完成。
但是,如果采用赋值语句定义函数,JavaScript 就会报错:
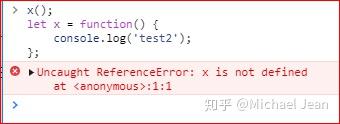
看过之前变量提升章节的话就应该明白,变量提升虽然存在,但是使用赋值语句,其提升的仅仅是变量本身,赋值不会同步上去,实际执行的语句变成了:
let x;
x();
x = function() {
console.log('test2');
};
故此在执行函数的第二步就会报错了。
同样由于函数名提升的存在,如果同一个函数多次声明,函数体将永远使用最后一个声明的内容,且前面的声明将自始无效:
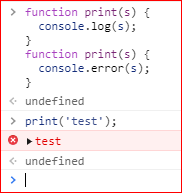
3 函数的属性和方法
3.1 name属性
函数的name属性会返回函数名,然而不同的情况下返回的函数名可能有不同,比如:
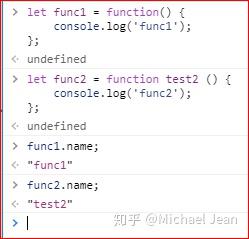
在上例当中,如果变量的值是一个具名函数,那么name属性返回function关键字之后的那个函数名——注意,真正的函数名还是func2,而test2这个名字只在函数体内部可用。
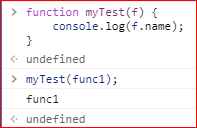
实际应用当中,name属性的一个用处,就是获取参数函数的名字:
3.2 length属性
函数的length属性返回函数预期传入的参数个数,即函数定义之中的参数个数:
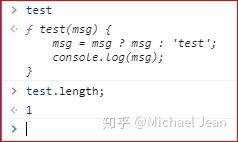
如上图,不管调用时输入了多少个参数,函数test的length属性始终等于1。
length属性提供了一种机制,判断定义时和调用时参数的差异,以便实现面向对象编程的“方法重载”(overload)。
但需要注意的是,由于在ES 6版本后,引入了参数默认值的概念,所有具有默认值的参数将无法通过length属性进行统计,如下图:
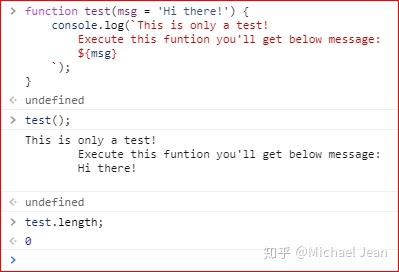
这是因为length属性的含义是,该函数预期传入的参数个数。某个参数指定默认值以后,预期传入的参数个数就不包括这个参数了。
这导致了ES 6之后的一些新增与参数有关的更新,都会造成这个古老的统计方法的失真。也就是说,一旦在函数参数上使用了ES 6之后的方法,就必须使用其他的手段对参数数量进行统计了,切记!
3.3 toString()方法
函数的toString方法返回一个字符串,内容是函数的源码;但是对于原生的函数(JavaScript预定义的函数)则会返回function 函数名 (){[native code]} :
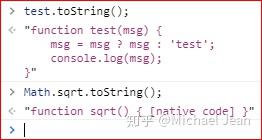
该方法的特别之处是,同时可以返回函数内部的注释,如下:
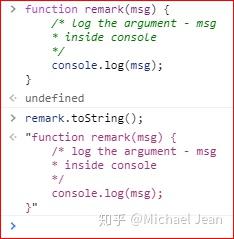
而在最新的ES 2019版本中,编写函数的所有注释(只要在function之后的注释)都会被toString()方法返回,因为该版本的标准中明确要求返回一模一样的原始代码,举例如下:
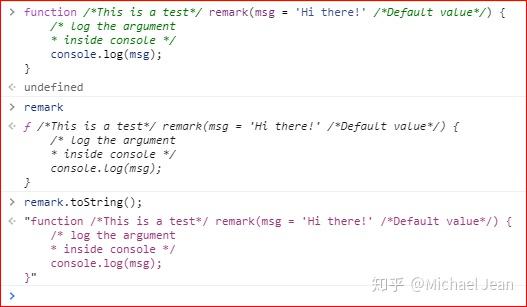
这里特别再强调一下:在开发时将注释写清楚对于其他人理解代码非常非常重要!
4 函数的作用域
4.1 作用域的定义
作用域(scope)指的是变量存在的范围。在 ES 5 的规范中,JavaScript 只有两种作用域:一种是全局作用域,变量在整个程序中一直存在,所有地方都可以读取;另一种是函数作用域,变量只在函数内部存在。
对于顶层函数来说,函数外部声明的变量就是全局变量(global variable),它可以在函数内部读取。
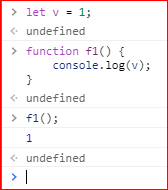
上面的代码表明,函数f1内部可以读取全局变量v。
在函数内部定义的变量,外部无法读取,称为“局部变量”(local variable)。
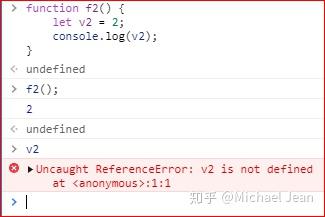
上面代码中,变量v2在函数内部定义,所以是一个局部变量,函数之外就无法读取。
函数内部定义的变量,会在该作用域内覆盖同名全局变量。
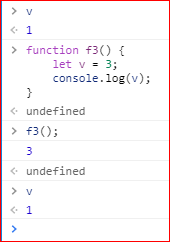
上面代码中,变量v同时在函数的外部和内部有定义。结果,在函数内部定义,局部变量v覆盖了全局变量v。
注意,对于var命令来说,局部变量只能在函数内部声明,在其他区块中声明,一律都是全局变量,故而建议使用let来替代var,以防止意外的声明全局变量。
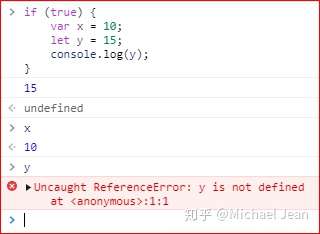
上面代码中,变量x在条件判断区块之中使用var声明,结果就是一个全局变量,可以在区块之外读取;而变量y使用let声明,结果只能在条件判断区块内生效,故此无法在区块外读取。
ES 6 又新增了作用域:一旦设置了参数的默认值,函数进行声明初始化时,参数会形成一个单独的作用域(context)。等到初始化结束,这个作用域就会消失。这种语法行为,在不设置参数默认值时,是不会出现的。

上面代码中,函数f4调用时,参数y = x形成一个单独的作用域。这个作用域里面,变量x本身没有定义,所以指向外层的全局变量x。函数调用时,函数体内部的局部变量x影响不到默认值变量x,所以最终输出的结果是y = 10。
此时,如果全局变量不存在,就会报错:
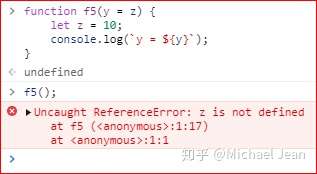
如上图中,f5的参数y默认值为z,但由于并未定义全局变量z,所以报错。
如果参数名和全局变量名相同,也会报错:
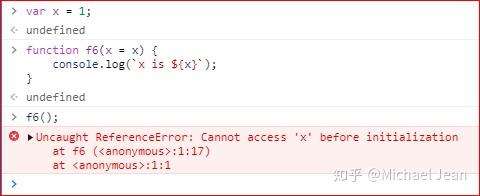
参数x = x形成一个单独作用域。实际执行的是let x = x,由于暂时性死区的原因,执行时会报错:变量x未初始化/未定义。
下一节会说到参数的具体用法,这些易错的知识就不再重复了,请务必留意不要踩坑。
4.2 函数体内部的变量提升
前面其实已经知道了使用var声明变量会造成变量提升,这个现象在函数体内部也会出现;留意,如果使用let或者const声明变量则不会有该现象,如下图:
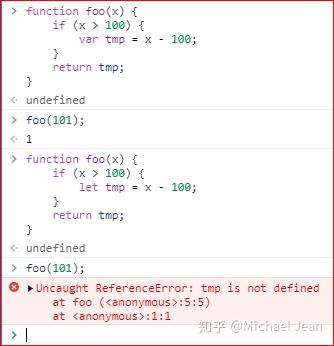
请务必留意这个区别。
4.3 函数本身的作用域
函数本身也是一个值,也有自己的作用域。它的作用域与变量一样,就是其声明时所在的作用域,与其运行时所在的作用域无关:
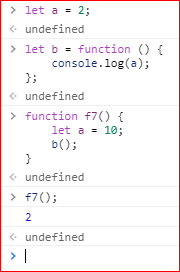
上面代码中,函数b是在函数f7的外部声明的,所以它的作用域绑定外层,内部变量a不会到函数f7体内取值,所以输出2,而不是10。
总之,函数执行时所在的作用域,是定义时的作用域,而不是调用时所在的作用域。
很容易犯错的一点是,如果函数A调用函数B,却没考虑到函数B不会引用函数A的内部变量:
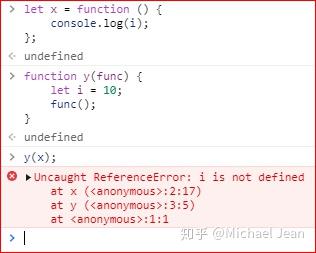
上面代码将函数x作为参数,传入函数y。但是,函数x是在函数y体外声明的,作用域绑定外层,因此找不到函数y的内部变量i,导致报错。
同样的,函数体内部声明的函数,作用域绑定函数体内部。
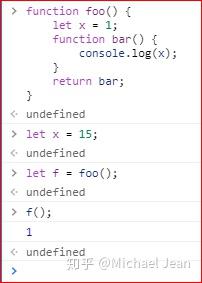
上面代码中,函数foo内部声明了一个函数bar,bar的作用域绑定foo。当我们在foo外部取出bar执行时,变量x指向的是foo内部的x,而不是foo外部的x。正是这种机制,构成了下文要说明的“闭包”现象。
5 参数
5.1 定义
函数有时候需要在运行时引用外部的数据,根据外部数据的不同,函数执行结果也会不同——这些数据就被称为参数,参数规定需放在函数名后面的括号()内——无论是声明还是调用——比如经常会用到的console.log(),括号内就是需要引用的参数,可以是变量,也可以是符合要求的其他数据,如下:

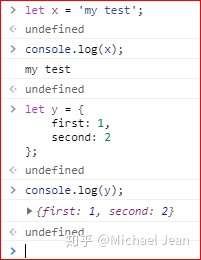
还有自己定义的函数,举例如下:

可以看到无论是预置函数还是自定义函数,其括号当中都有引用的值,这就是参数了。
在实际使用当中,我们也会看到没有使用参数的函数,比如:

这是因为函数参数不是必需的,JavaScript 允许省略参数;同样已经定义好参数个数的函数也是可以省略的,如下:

上面代码的函数f定义了两个参数,但是运行时无论提供多少个参数(或者不提供参数),JavaScript 都不会报错。省略的参数的值就变为undefined。这里由于省略了参数,故而运算结果会变为NaN,请参考数值类型那一章的内容;
但是,没有办法只省略靠前的参数,而保留靠后的参数。如果一定要省略靠前的参数,只有显式传入undefined。
5.2 同名参数
如果有同名的参数,则取最后出现的那个值。
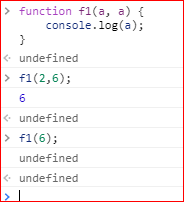
上面代码中,函数f1有两个参数,且参数名都是a。取值的时候,以后面的a为准,即使后面的a没有值或被省略,也是以其为准。
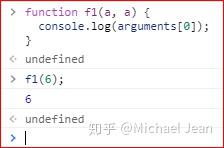
调用函数f1的时候,没有提供第二个参数,a的取值就变成了undefined。这时,如果要获得第一个a的值,可以使用arguments对象。
5.3 参数默认值
如果有留意到之前实例的话,你会发现我使用了两种方式来写一个函数的参数默认值,下面我把两种方法混合一下:
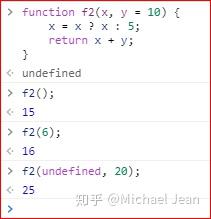
这里,x的默认参数值使用了ES 6之前的写法;而y的默认值则使用了ES 6之后的写法。
相比较来说,y这样的写法更加符合人们的使用习惯,因为更加简洁,所以也更容易使用和阅读,可以立刻意识到哪些参数是可以省略的,而不需要具体查看函数体或者API文档;而且有利于将来的代码优化,譬如未来在对外接口中彻底拿掉这个参数,也不会导致以前的代码无法运行。
这里有一些需要注意的地方:
- 参数变量是默认声明的,所以不能用let 或者const再次声明:
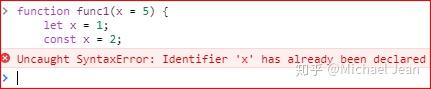
- 使用参数默认值的时候,函数不能有同名参数:

- 参数默认值不是传值的,而是每次都重新计算默认值表达式的值:

上例中,参数y的默认值是x + 1,每次调用函数func1,都会重新计算x + 1,而不是默认y等于51
同时,参数默认值是可以和对象解构赋值一起使用的,解构赋值是之后会提到的一个ES 6特性,比如如下实例:
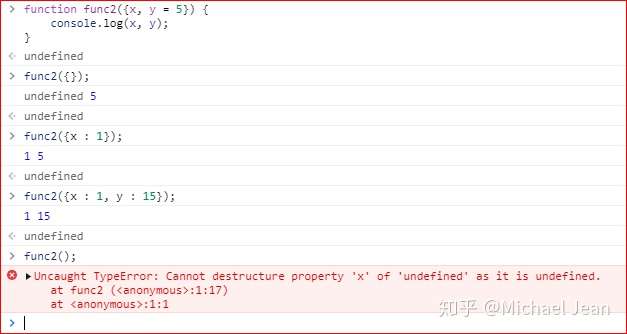
上面代码只使用了对象的解构赋值默认值,没有使用函数参数的默认值。只有当函数func2的参数是一个对象时,变量x和y才会通过解构赋值生成。如果函数func2调用时没提供参数,变量x和y就不会生成,从而报错。通过提供函数参数的默认值,就可以避免这种情况
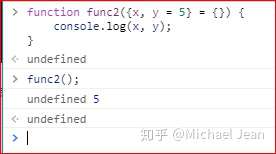
这是在ES 6当中使得代码更加简洁的一种写法,如果不使用默认值写法,就可能造成下述区别:
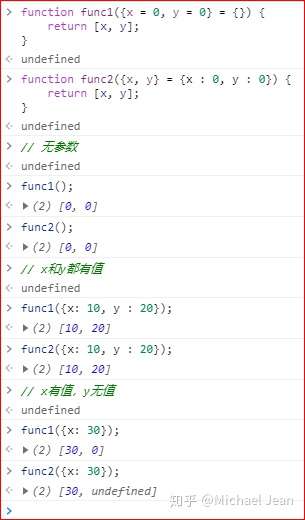
请认真留意区别之处。
5.4 arguments对象
- 定义
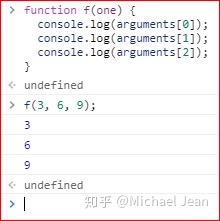
由于 JavaScript 允许函数有不定数目的参数,所以需要一种机制,可以在函数体内部读取所有参数。这就是arguments对象的由来。
arguments对象包含了函数运行时的所有参数,arguments[0]就是第一个参数,arguments[1]就是第二个参数,以此类推。这个对象只有在函数体内部,才可以使用。
最初因为这个对象并不严谨的设定,是可以直接在函数体内修改参数的,后来引入严格模式,使得修改可以被屏蔽了:
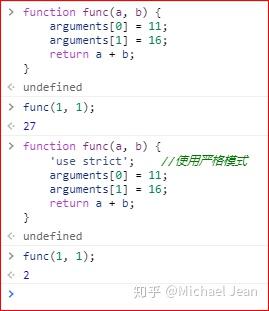
- 和数组的区别
需要注意的是,虽然arguments很像数组,但它是一个对象。数组专有的方法(比如slice和forEach),不能在arguments对象上直接使用。
如果要让arguments对象使用数组方法,真正的解决方法是将arguments转为真正的数组。下面是两种常用的转换方法:slice方法和逐一填入新数组:
let args = Array.prototype.slice.call(arguments);
// 或者
let args = [];
for (let i = 0; i < arguments.length; i++) {
args.push(arguments[i]);
}
- callee属性
arguments对象带有一个callee属性,返回它所对应的原函数。
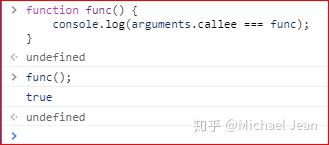
可以通过arguments.callee,达到调用函数自身的目的。这个属性在严格模式里面是禁用的,因此不建议使用。
5.4 rest参数
由于ES 6之前所有的函数参数都必须是预先定义好的,这就造成数量超出预定义的参数很可能不作响应或者造成函数出错,于是在ES 6之后引入了rest参数,其形式为...变量名,可以用来获取多余的函数,这样就不需要使用arguments对象了:
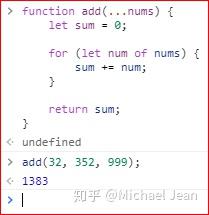
rest 参数搭配的变量是一个数组,该变量将多余的参数放入数组中。如上面的代码中,利用rest参数,可以向其中传入任意数目的参数。
注意:rest参数之后不能再有其他的参数,否则会报错:

6 函数的特殊知识点
因为这个草稿在我手里放了太久,有人提意见了,所以我先把没写完的发出来,最后这部分我找个时间补充完整,抱歉!
6.1 闭包
其实就算不是专门做前端开发的IT人,有的时候也会听到这个词,挺有意思的,闭包(closure)其实就是JavaScript的一个特色,也是一个单点,很多JS的高级应用都要依靠闭包来实现的;不知怎么就到处流传了起来,以至于我有非开发类的朋友都问过我它是个什么东东——我解释一通之后,发现他满脸茫然……
对不起啦!我这里尽量好好的通俗的解释一下:理解闭包,首先必须理解变量作用域。前面提到,JavaScript 有两种作用域:全局作用域和函数作用域。
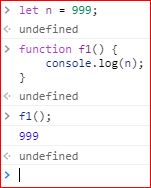
函数内部可以直接读取全局变量,比如下面的例子,函数f1可以读取全局变量n:
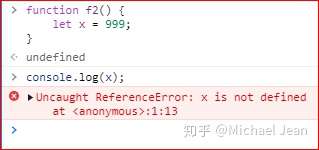
但是函数外部无法读取函数内声明的变量,如下例,函数f2内部声明的变量x,函数外无法读取:
实际编程的时候,我们往往需要得到函数内的局部变量,由于直接获取是不可能的,只有自己像一个变通的方法了,譬如在函数内部再定义一个函数:
function f1() {
var x = 999;
function f2() {
console.log(x); // 999
}
}
上面代码中,函数f3就在函数f2内部,这时f2内部的所有局部变量,对f3都是可见的。但是反过来就不行,f3内部的局部变量,对f2就是不可见的。这就是 JavaScript 语言特有的"链式作用域"结构(chain scope),子对象会一级一级地向上寻找所有父对象的变量。所以,父对象的所有变量,对子对象都是可见的,反之则不成立。
既然f3可以读取f2的局部变量,那么只要把f3作为返回值,我们不就可以在f2外部读取它的内部变量了吗?比如下面的例子,f2的返回值就是f3,由于f3可以读取f2的内部变量,所以我们就可以在外部获得x这个f2的内部变量了:
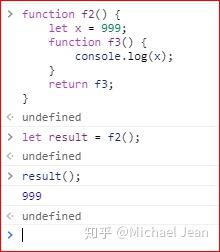
这里,闭包就是函数f3,即能够读取其他函数内部变量的函数。由于在 JavaScript 语言中,只有函数内部的子函数才能读取内部变量,因此可以把闭包简单理解成“定义在一个函数内部的函数”。闭包最大的特点,就是它可以“记住”诞生的环境,比如f3记住了它诞生的环境f2,所以从f3可以得到f2的内部变量。在本质上,闭包就是将函数内部和函数外部连接起来的一座桥梁。
闭包的最大用处有两个,一个是可以读取函数内部的变量,另一个就是让这些变量始终保持在内存中,即闭包可以使得它诞生环境一直存在。请看下面的例子,闭包使得内部变量记住上一次调用时的运算结果:
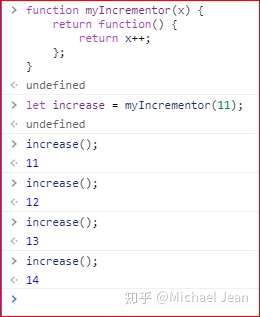
上面代码中,x是函数myIncrementor的内部变量。通过闭包,x的状态被保留了,每一次调用都是在上一次调用的基础上进行计算。从中可以看到,闭包increase使得函数myIncrementor的内部环境,一直存在。所以,闭包可以看作是函数内部作用域的一个接口。
为什么会这样呢?原因就在于increase始终在内存中,而increase的存在依赖于myIncrementor,因此也始终在内存中,不会在调用结束后,被垃圾回收机制回收。
闭包的另一个用处,是封装对象的私有属性和私有方法,如下面的代码中,函数Person的内部变量_age,通过闭包getAge和setAge,变成了返回对象p1的私有变量:
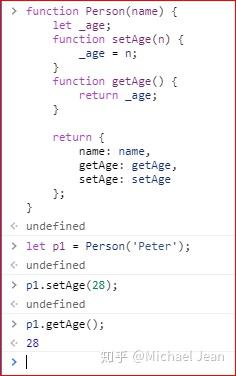
注意,外层函数每次运行,都会生成一个新的闭包,而这个闭包又会保留外层函数的内部变量,所以内存消耗很大。因此不能滥用闭包,否则会造成网页的性能问题。
6.2 立即调用函数
在 JavaScript 中,圆括号()是一种运算符,跟在函数名之后,表示调用该函数。比如,print()就表示调用print函数。
有时,我们需要在定义函数之后,立即调用该函数。这时,你不能在函数的定义之后加上圆括号,这会产生语法错误:

产生这个错误的原因是,function这个关键字即可以当作语句,也可以当作表达式。
// 语句
function f() {}
// 表达式
var f = function f() {}
为了避免解析上的歧义,JavaScript 引擎规定,如果function关键字出现在行首,一律解释成语句。因此,JavaScript 引擎看到行首是function关键字之后,认为这一段都是函数的定义,不应该以圆括号结尾,所以就报错了。
解决方法就是不要让function出现在行首,让引擎将其理解成一个表达式。最简单的处理,就是将其放在一个圆括号里面。
(function(){ /* code */ }());
// 或者
(function(){ /* code */ })();
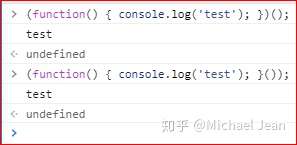
上面两种写法都是以圆括号开头,引擎就会认为后面跟的是一个表示式,而不是函数定义语句,所以就避免了错误。这就叫做“立即调用的函数表达式”(Immediately-Invoked Function Expression),简称 IIFE。
注意,上面两种写法最后的分号都是必须的。如果省略分号,遇到连着两个 IIFE,可能就会报错。
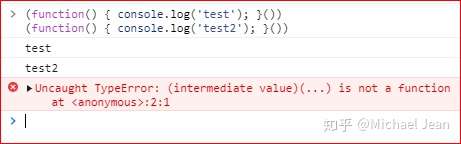
上面代码的两行之间没有分号,JavaScript 会将它们连在一起解释,将第二行解释为第一行的参数。
推而广之,任何让解释器以表达式来处理函数定义的方法,都能产生同样的效果,比如下面三种写法。

甚至像下面这样写,也是可以的。
!function () { /* code */ }();
~function () { /* code */ }();
-function () { /* code */ }();
+function () { /* code */ }();
通常情况下,只对匿名函数使用这种“立即执行的函数表达式”。它的目的有两个:一是不必为函数命名,避免了污染全局变量;二是 IIFE 内部形成了一个单独的作用域,可以封装一些外部无法读取的私有变量。
// 写法一
var tmp = newData;
processData(tmp);
storeData(tmp);
// 写法二
(function () {
var tmp = newData;
processData(tmp);
storeData(tmp);
}());
上面代码中,写法二比写法一更好,因为完全避免了污染全局变量。
6.3 eval
6.3.1 eval = evil ??
eval命令接受一个字符串作为参数,并将这个字符串当作语句执行:
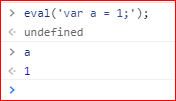
上面代码将字符串当作语句运行,生成了变量a。
不过你可能有留意到,在上面这个例子里面,并没有使用let进行声明,这是因为let命令的作用域和var不同,它仅能在当前域生效,所以如果这里使用let,将自始无效:
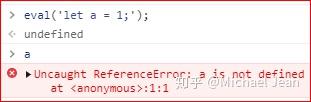
如果参数字符串无法当作语句运行,那么就会报错:
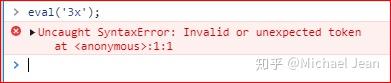
放在eval中的字符串,应该有独自存在的意义,不能用来与eval以外的命令配合使用。举例来说,下面的代码将会报错:

如果eval的参数不是字符串,那么会原样返回:

eval没有自己的作用域,都在当前作用域内执行,因此可能会修改当前作用域的变量的值,造成安全问题:
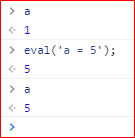
如上,eval命令直接修改了外部变量a的值;由于这个原因,eval有很明显的安全风险。甚至有“eval = evil”的说法,让一个个JS小白战栗发抖。
为了防止这种风险,JavaScript 规定,如果使用严格模式,eval内部声明的变量,不会影响到外部作用域:

上面代码中,函数f内部是严格模式,这时eval内部声明的test变量,就不会影响到外部。
不过,即使在严格模式下,eval依然可以读写当前作用域的变量:

上面代码中,严格模式下,eval内部还是改写了外部变量,可见安全风险依然存在。
总之,eval的本质是在当前作用域之中,注入代码。由于安全风险和不利于 JavaScript 引擎优化执行速度,所以一般不推荐使用。通常情况下,eval最常见的场合是解析 JSON 数据的字符串,不过正确的做法应该是使用原生的JSON.parse方法。
6.3.2 eval的别名调用
前面说过eval不利于引擎优化执行速度。更麻烦的是,还有下面这种情况,引擎在静态代码分析的阶段,根本无法分辨执行的是eval。
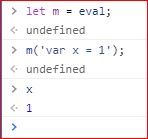
上面代码中,变量m是eval的别名。静态代码分析阶段,引擎分辨不出m('var x = 1')执行的是eval命令。
为了保证eval的别名不影响代码优化,JavaScript 的标准规定,凡是使用别名执行eval,eval内部一律是全局作用域:
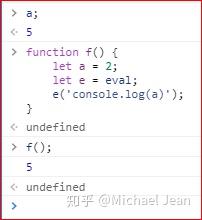
上面代码中,eval是别名调用,所以即使它是在函数中,它的作用域还是全局作用域,因此输出的a为全局变量。这样的话,引擎就能确认e()不会对当前的函数作用域产生影响,优化的时候就可以把这一行排除掉。
eval的别名调用的形式五花八门,只要不是直接调用,都属于别名调用,因为引擎只能分辨eval()这一种形式是直接调用;故此千万要留意!
eval.call(null, '...')
window.eval('...')
(1, eval)('...')
(eval, eval)('...')
上面这些形式都是eval的别名调用,作用域都是全局作用域。
6.4 箭头函数
6.4.1 基础使用
从ES 6开始,JavaScript允许使用“箭头”(=>)定义函数:
var f = v => v;
// 等同于
var f = function (v) {
return v;
};
如果箭头函数不需要参数或需要多个参数,就使用一个圆括号代表参数部分:
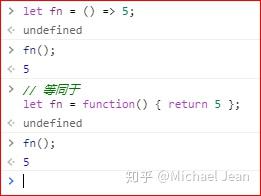
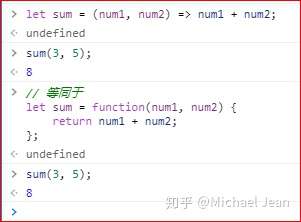
如果箭头函数的代码块部分多于一条语句,就要使用大括号将它们括起来,并且使用return语句返回。
let sum = (num1, num2) => { return num1 + num2; }
由于大括号被解释为代码块,所以如果箭头函数直接返回一个对象,必须在对象外面加上括号,否则会报错:

下面是一种特殊情况,虽然可以运行,但会得到错误的结果:
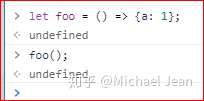
上面代码中,原始意图是返回一个对象{ a: 1 },但是由于引擎认为大括号是代码块,所以执行了一行语句a: 1。这时,a可以被解释为语句的标签,因此实际执行的语句是1;,然后函数就结束了,没有返回值。
如果箭头函数只有一行语句,且不需要返回值,可以采用下面的写法,就不用写大括号了:
let fn = () => void doesNotReturn();
箭头函数可以与变量解构结合使用:
const full = ({ first, last }) => first + ' ' + last;
// 等同于
function full(person) {
return person.first + ' ' + person.last;
}
箭头函数使得表达更加简洁:
const isEven = n => n % 2 === 0;
const square = n => n * n;
上面代码只用了两行,就定义了两个简单的工具函数。如果不用箭头函数,可能就要占用多行,而且还不如现在这样写醒目。
箭头函数的一个用处是简化回调函数。
// 正常函数写法
[1,2,3].map(function (x) {
return x * x;
});
// 箭头函数写法
[1,2,3].map(x => x * x);
另一个例子是
// 正常函数写法
var result = values.sort(function (a, b) {
return a - b;
});
// 箭头函数写法
var result = values.sort((a, b) => a - b);
下面是 rest 参数与箭头函数结合的例子。
const numbers = (...nums) => nums;
numbers(1, 2, 3, 4, 5)
// [1,2,3,4,5]
const headAndTail = (head, ...tail) => [head, tail];
headAndTail(1, 2, 3, 4, 5)
// [1,[2,3,4,5]]
6.4.2 使用注意点
箭头函数有几个使用注意点。
- 函数体内的this对象,就是定义时所在的对象,而不是使用时所在的对象。
- 不可以当作构造函数,也就是说,不可以使用new命令,否则会抛出一个错误。
- 不可以使用arguments对象,该对象在函数体内不存在。如果要用,可以用 rest 参数代替。
- 不可以使用yield命令,因此箭头函数不能用作 Generator 函数。
上面四点中,第一点尤其值得注意——this对象的指向是可变的,但是在箭头函数中,它是固定的:

上面代码中,setTimeout的参数是一个箭头函数,这个箭头函数的定义生效是在bar函数生成时,而它的真正执行要等到 100 毫秒后。如果是普通函数,执行时this应该指向全局对象window,这时应该输出33。但是,箭头函数导致this总是指向函数定义生效时所在的对象(本例是{id: 100}),所以输出的是100。
箭头函数可以让setTimeout里面的this,绑定定义时所在的作用域,而不是指向运行时所在的作用域。下面是另一个例子。
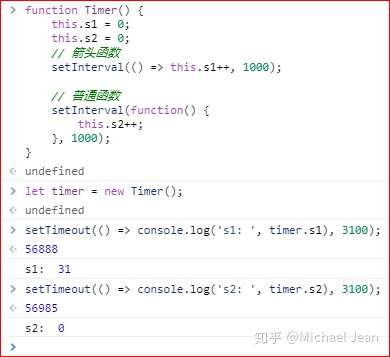
上面代码中,Timer函数内部设置了两个定时器,分别使用了箭头函数和普通函数。前者的this绑定定义时所在的作用域(即Timer函数),后者的this指向运行时所在的作用域(即全局对象)。所以,3100 毫秒之后,timer.s1被更新了 31 次,而timer.s2一次都没更新。
箭头函数可以让this指向固定化,这种特性很有利于封装回调函数。下面是一个例子,DOM 事件的回调函数封装在一个对象里面。
var handler = {
id: '123456',
init: function() {
document.addEventListener('click',
event => this.doSomething(event.type), false);
},
doSomething: function(type) {
console.log('Handling ' + type + ' for ' + this.id);
}
};
上面代码的init方法中,使用了箭头函数,这导致这个箭头函数里面的this,总是指向handler对象。否则,回调函数运行时,this.doSomething这一行会报错,因为此时this指向document对象。
this指向的固定化,并不是因为箭头函数内部有绑定this的机制,实际原因是箭头函数根本没有自己的this,导致内部的this就是外层代码块的this。正是因为它没有this,所以也就不能用作构造函数。
所以,箭头函数转成 ES 5 的代码如下。
// ES6
function foo() {
setTimeout(() => {
console.log('id:', this.id);
}, 100);
}
// ES5
function foo() {
var _this = this;
setTimeout(function () {
console.log('id:', _this.id);
}, 100);
}
上面代码中,转换后的 ES 5 版本清楚地说明了,箭头函数里面根本没有自己的this,而是引用外层的this。
再来看看,请问下面的代码之中有几个this?
function foo() {
return () => {
return () => {
return () => {
console.log('id:', this.id);
};
};
};
}
var f = foo.call({id: 1});
var t1 = f.call({id: 2})()(); // id: 1
var t2 = f().call({id: 3})(); // id: 1
var t3 = f()().call({id: 4}); // id: 1
上面代码之中,只有一个this,就是函数foo的this,所以t1、t2、t3都输出同样的结果。因为所有的内层函数都是箭头函数,都没有自己的this,它们的this其实都是最外层foo函数的this。
除了this,以下三个变量在箭头函数之中也是不存在的,指向外层函数的对应变量:arguments、super、new.target。
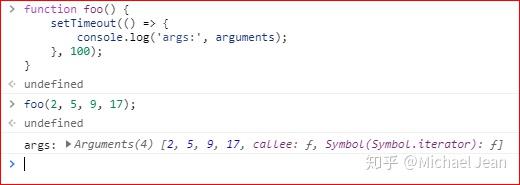
上面代码中,箭头函数内部的变量arguments,其实是函数foo的arguments变量。
另外,由于箭头函数没有自己的this,所以当然也就不能用call()、apply()、bind()这些方法去改变this的指向。

上面代码中,箭头函数没有自己的this,所以bind方法无效,内部的this指向外部的this。
长期以来,JavaScript 语言的this对象一直是一个令人头痛的问题,在对象方法中使用this,必须非常小心。箭头函数”绑定”this,很大程度上解决了这个困扰。
6.4.3 不适用场合
由于箭头函数使得this从“动态”变成“静态”,下面两个场合不应该使用箭头函数。
第一个场合是定义对象的方法,且该方法内部包括this。
const cat = {
lives: 9,
jumps: () => {
this.lives--;
}
}
上面代码中,cat.jumps()方法是一个箭头函数,这是错误的。调用cat.jumps()时,如果是普通函数,该方法内部的this指向cat;如果写成上面那样的箭头函数,使得this指向全局对象,因此不会得到预期结果。这是因为对象不构成单独的作用域,导致jumps箭头函数定义时的作用域就是全局作用域。
第二个场合是需要动态this的时候,也不应使用箭头函数。
var button = document.getElementById('press');
button.addEventListener('click', () => {
this.classList.toggle('on');
});
上面代码运行时,点击按钮会报错,因为button的监听函数是一个箭头函数,导致里面的this就是全局对象。如果改成普通函数,this就会动态指向被点击的按钮对象。
另外,如果函数体很复杂,有许多行,或者函数内部有大量的读写操作,不单纯是为了计算值,这时也不应该使用箭头函数,而是要使用普通函数,这样可以提高代码可读性。
6.4.4 嵌套的箭头函数
箭头函数内部,还可以再使用箭头函数。下面是一个 ES 5 语法的多重嵌套函数:

上面这个函数,可以使用箭头函数改写:
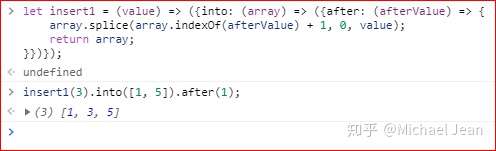
下面是一个部署管道机制(pipeline)的例子,即前一个函数的输出是后一个函数的输入。
const pipeline = (...funcs) =>
val => funcs.reduce((a, b) => b(a), val);
const plus1 = a => a + 1;
const mult2 = a => a * 2;
const addThenMult = pipeline(plus1, mult2);
addThenMult(5)
// 12
如果觉得上面的写法可读性比较差,也可以采用下面的写法。
const plus1 = a => a + 1;
const mult2 = a => a * 2;
mult2(plus1(5))
// 12
箭头函数还有一个功能,就是可以很方便地改写 λ 演算。
// λ演算的写法
fix = λf.(λx.f(λv.x(x)(v)))(λx.f(λv.x(x)(v)))
// ES 6的写法
let fix = f => (x => f(v => x(x)(v)))
(x => f(v => x(x)(v)));
上面两种写法,几乎是一一对应的。由于 λ 演算对于计算机科学非常重要,这使得我们可以用 ES 6 作为替代工具,探索计算机科学。
6.5 递归、尾调用、尾递归
6.5.1 递归
函数可以调用自身,这就是递归(recursion)。下面就是通过递归,计算斐波那契数列的代码。

上面代码中,fib函数内部又调用了fib,计算得到斐波那契数列的第6个元素是8。
这里请一定要注意,这种方式很容易造成大量运算堆积从而使得网页、应用死锁的问题(这里也不截图了,因为页面死锁截图看不出来),所以推荐使用尾递归,请参考后文。
6.5.2 尾调用
尾调用(Tail Call)是函数式编程的一个重要概念,本身非常简单,一句话就能说清楚,就是指某个函数的最后一步是调用另一个函数。
function f(x){
return g(x);
}
上面代码中,函数f的最后一步是调用函数g,这就叫尾调用。
以下三种情况,都不属于尾调用。
// 情况一
function f(x){
let y = g(x);
return y;
}
// 情况二
function f(x){
return g(x) + 1;
}
// 情况三
function f(x){
g(x);
}
上面代码中,情况一是调用函数g之后,还有赋值操作,所以不属于尾调用,即使语义完全一样。情况二也属于调用后还有操作,即使写在一行内。情况三等同于下面的代码。
function f(x){
g(x);
return undefined;
}
尾调用不一定出现在函数尾部,只要是最后一步操作即可。
function f(x) {
if (x > 0) {
return m(x)
}
return n(x);
}
上面代码中,函数m和n都属于尾调用,因为它们都是函数f的最后一步操作。
尾调用之所以与其他调用不同,就在于它的特殊的调用位置。
我们知道,函数调用会在内存形成一个“调用记录”,又称“调用帧”(call frame),保存调用位置和内部变量等信息。如果在函数A的内部调用函数B,那么在A的调用帧上方,还会形成一个B的调用帧。等到B运行结束,将结果返回到A,B的调用帧才会消失。如果函数B内部还调用函数C,那就还有一个C的调用帧,以此类推。所有的调用帧,就形成一个“调用栈”(call stack)。
尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用帧,因为调用位置、内部变量等信息都不会再用到了,只要直接用内层函数的调用帧,取代外层函数的调用帧就可以了。
function f() {
let m = 1;
let n = 2;
return g(m + n);
}
f();
// 等同于
function f() {
return g(3);
}
f();
// 等同于
g(3);
上面代码中,如果函数g不是尾调用,函数f就需要保存内部变量m和n的值、g的调用位置等信息。但由于调用g之后,函数f就结束了,所以执行到最后一步,完全可以删除f(x)的调用帧,只保留g(3)的调用帧。
这就叫做“尾调用优化”(Tail call optimization),即只保留内层函数的调用帧。如果所有函数都是尾调用,那么完全可以做到每次执行时,调用帧只有一项,这将大大节省内存。这就是“尾调用优化”的意义。
注意,只有不再用到外层函数的内部变量,内层函数的调用帧才会取代外层函数的调用帧,否则就无法进行“尾调用优化”。
function addOne(a){
var one = 1;
function inner(b){
return b + one;
}
return inner(a);
}
上面的函数不会进行尾调用优化,因为内层函数inner用到了外层函数addOne的内部变量one。
注意,目前只有 Safari 浏览器支持尾调用优化,Chrome 和 Firefox 都不支持。
6.5.3 尾递归
函数调用自身,称为递归。如果尾调用自身,就称为尾递归。
递归非常耗费内存,因为需要同时保存成千上百个调用帧,很容易发生“栈溢出”错误(stack overflow)。但对于尾递归来说,由于只存在一个调用帧,所以永远不会发生“栈溢出”错误。
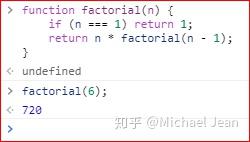
上面代码是一个阶乘函数,计算n的阶乘,最多需要保存n个调用记录,复杂度 O(n) 。
如果改写成尾递归,只保留一个调用记录,复杂度 O(1) 。
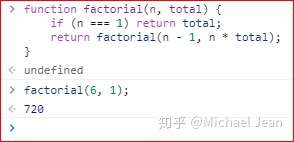
还有一个比较著名的例子,就是计算斐波那契数列,也能充分说明尾递归优化的重要性。
尾递归优化过的斐波那契数列实现如下。
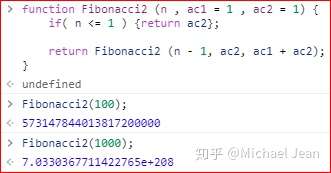
由此可见,“尾调用优化”对递归操作意义重大,所以一些函数式编程语言将其写入了语言规格。ES 6 亦是如此,第一次明确规定,所有 ECMAScript 的实现,都必须部署“尾调用优化”。这就是说,ES 6 中只要使用尾递归,就不会发生栈溢出(或者层层递归造成的超时),相对节省内存。
- 递归函数的改写
尾递归的实现,往往需要改写递归函数,确保最后一步只调用自身。做到这一点的方法,就是把所有用到的内部变量改写成函数的参数。比如上面的例子,阶乘函数 factorial 需要用到一个中间变量total,那就把这个中间变量改写成函数的参数。这样做的缺点就是不太直观,第一眼很难看出来,为什么计算6的阶乘,需要传入两个参数6和1?
两个方法可以解决这个问题。方法一是在尾递归函数之外,再提供一个正常形式的函数。
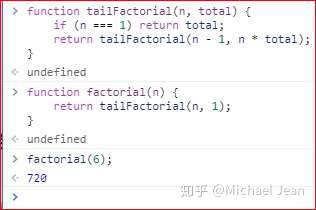
上面代码通过一个正常形式的阶乘函数factorial,调用尾递归函数tailFactorial,看起来就正常多了。
函数式编程有一个概念,叫做柯里化(currying),意思是将多参数的函数转换成单参数的形式。这里也可以使用柯里化。
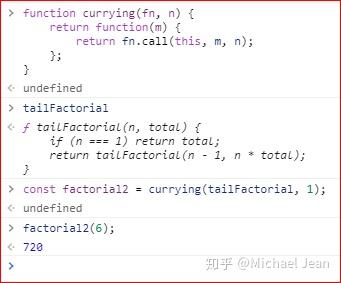
上面代码通过柯里化,将尾递归函数tailFactorial变为只接受一个参数的factorial。
第二种方法就简单多了,就是采用 ES 6 的函数默认值。
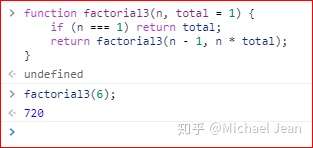
上面代码中,参数total有默认值1,所以调用时不用提供这个值。
总结一下,递归本质上是一种循环操作。纯粹的函数式编程语言没有循环操作命令,所有的循环都用递归实现,这就是为什么尾递归对这些语言极其重要。对于其他支持“尾调用优化”的语言(比如 Lua,ES 6),只需要知道循环可以用递归代替,而一旦使用递归,就最好使用尾递归。
- 严格模式
ES 6 的尾调用优化只在严格模式下开启,正常模式是无效的。
这是因为在正常模式下,函数内部有两个变量,可以跟踪函数的调用栈。
- func.arguments:返回调用时函数的参数。
- func.caller:返回调用当前函数的那个函数。
尾调用优化发生时,函数的调用栈会改写,因此上面两个变量就会失真。严格模式禁用这两个变量,所以尾调用模式仅在严格模式下生效。

- 尾递归优化的实现
尾递归优化只在严格模式下生效,那么正常模式下,或者那些不支持该功能的环境中,有没有办法也使用尾递归优化呢?回答是可以的,就是自己实现尾递归优化。
它的原理非常简单。尾递归之所以需要优化,原因是调用栈太多,造成溢出,那么只要减少调用栈,就不会溢出。怎么做可以减少调用栈呢?就是采用“循环”换掉“递归”。
下面是一个正常的递归函数。

上面代码中,sum是一个递归函数,参数x是需要累加的值,参数y控制递归次数。一旦指定sum递归 100000 次,就会报错,提示超出调用栈的最大次数。
蹦床函数(trampoline)可以将递归执行转为循环执行。
function trampoline(f) {
while (f && f instanceof Function) {
f = f();
}
return f;
}
上面就是蹦床函数的一个实现,它接受一个函数f作为参数。只要f执行后返回一个函数,就继续执行。注意,这里是返回一个函数,然后执行该函数,而不是函数里面调用函数,这样就避免了递归执行,从而就消除了调用栈过大的问题。
然后,要做的就是将原来的递归函数,改写为每一步返回另一个函数。
function sum(x, y) {
if (y > 0) {
return sum.bind(null, x + 1, y - 1);
} else {
return x;
}
}
上面代码中,sum函数的每次执行,都会返回自身的另一个版本。
现在,使用蹦床函数执行sum,就不会发生调用栈溢出。
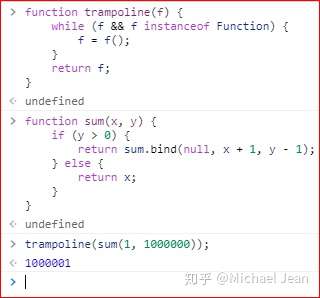
蹦床函数并不是真正的尾递归优化,下面的实现才是。
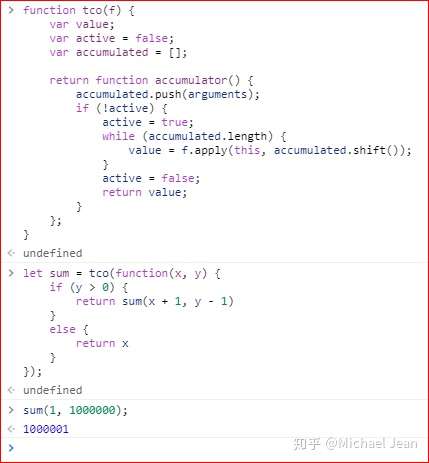
上面代码中,tco函数是尾递归优化的实现,它的奥妙就在于状态变量active。默认情况下,这个变量是不激活的。一旦进入尾递归优化的过程,这个变量就激活了。然后,每一轮递归sum返回的都是undefined,所以就避免了递归执行;而accumulated数组存放每一轮sum执行的参数,总是有值的,这就保证了accumulator函数内部的while循环总是会执行。这样就很巧妙地将“递归”改成了“循环”,而后一轮的参数会取代前一轮的参数,保证了调用栈只有一层。
评论
发表评论