书接上文,这次因为要处理邮件什么的更新晚了几天,今天把它补上。
之前了解过了数值,现在轮到了文本——字符串:
1 定义
1.1 基础字符串
在JavaScript当中,字符串就是放在两个单引号或者双引号当中的零个或多个字符,比如:
''
"test"
'Strings'
"!!!"
在单引号或者双引号内部,也可以分别使用对方,比如,单引号内使用双引号,或者双引号内使用单引号,如:
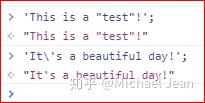
'This is a "test"!'
"This is another 'test'!"
而如果要在单引号内使用单引号,或者双引号内使用双引号,则需要加上\(反斜杠)进行转义,如:
'It\'s a beautiful day!'
"Should I say \"Hello\" to him?"
惯例上,由于HTML使用双引号标识属性,开发者会自觉在JavaScript当中使用单引号标识字符串;我自然也不例外。不过并不排除有人会喜欢使用双引号进行标识,当然这也是可以的,不过在实际开发过程当中,最好始终保持同一种风格,而不要一时使用单引号,一时使用双引号。
另外,从ES 6版本开始,JavaScript支持了新的写法——模板字符串(template string)是增强版的字符串,用反引号`标识。它可以当作普通字符串使用,也可以用来定义多行字符串,或者在字符串中嵌入变量:

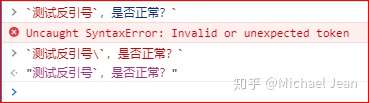
同样的,如果需要在模板字符串内(即两个反引号``内)使用反引号,需要加上反斜杠进行转义:
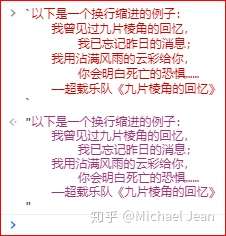
比较特殊的地方在于,模板字符串内的字符串可以保持换行、缩进的多少:
最后,在模板字符串内部,使用${}可以直接调用变量、表达式,这样的使用减少了字符串+变量/表达式的拼接,实在是居家旅行之必备方式:

1.2 字符串拼接
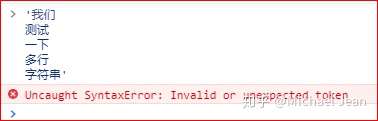
实际使用中,其实会有很多情况下需要使用多组字符串进行拼接,不过如果直接在引号当中分行,是会报错的,如:
这种时候,如果仅仅只是想生成单行字符串,可以在每行字符结尾添加\(反斜杠),这样会直接生成单行字符串且不报错,如:

或者也可以使用+号进行字符串拼接,如:

如果想保持原样多行输出,除了下文即将提出的换行转义符\n,其实也可以采用一种利用注释的变通方法,如下:

不过可以从后续的方法看出,\n仍然是分行的基础,故而这种方式太过繁复,并不建议。
在ES 6引入模板字符串之后,这个问题变得更容易解决了,因为在反引号``内部本身就已经支持了多行文本,以及变量调用;在有可能的情况下,建议尽量使用模板字符串。
2 转义
在字符串构造的时候,其实需要很多特殊的功能,包括换行、制表、换页、回车等等,直接使用字符串本身是无法构造成功的,故而需要转义符的存在——特殊字符\(反斜杠);下面用一个简单的列表把相关功能标示出来:
- \0 :null(\u0000)
- \b :后退键(\u0008)
- \f :换页符(\u000C)
- \n :换行符(\u000A)
- \r :回车键(\u000D)
- \t :制表符(\u0009)
- \v :垂直制表符(\u000B)
- \' :单引号(\u0027)
- \" :双引号(\u0022)
- \\ :反斜杠(\u005c)
举个简单的例子:
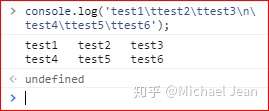
上图中使用了制表符\t以及换行符\n,同时为了代码易读性,分成了两行编写,并使用了\将其连接,最终结果就是分为了两行三列的建议表单。
除上面的情况之外,其实还有三种比较特殊的用法,本质上都是引用了Unicode的码点:
- \000 - \777 —— 在反斜杠后包括3位的8进制数值,也可以代表不同的特殊符号,从000到777共256种,简单举例如下图:

- \x00 - \xFF —— 在反斜杠后加上小写字母x,以及2位的16进制数值,从00到FF也是256种,简单举例如下图:

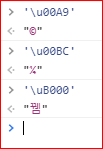
- \u0000 - \uFFFF —— 在反斜杠后加上小写字母u,以及4位的16进制数值,从0000到FFFF共65536种,这也就有可能添加上了各种东方语言文字,比如\uB000就是韩语的”뀀“:
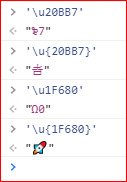
这里需要补充一点,ES 6开始支持了更高位数的十六进制unicode字符,只需要使用大括号{}将其括住即可正确识别,下图就是使用大括号和不使用大括号的对比:
有了如上的方法之后,JavaScript从ES 6版本开始,拥有了6种表示同一个字符的方式:

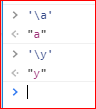
当然转义符如果用在了非预先定义的字符上时,就可能被引擎直接忽略掉,如:
3 字符串与数组
在JavaScript的定义当中,字符串其实也可以考虑为字符数组(数组的概念之后会涉及到),因此可以使用数组的方括号运算符,用来返回某个位置的字符(位置编号从0开始),譬如:
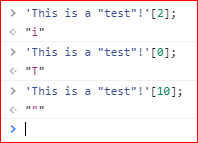
如果方括号中的数字超过字符串的长度,或者方括号中根本不是数字,则返回undefined。

不过字符串可以当成是有只读属性的数组,故而无法通过该方式修改其中的单个字符:
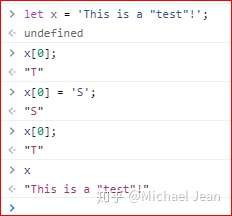
在普通模式下,尽管并未报错,但这些修改都默默地失败了,哈哈……
而在严格模式下,则会产生如下错误提示:
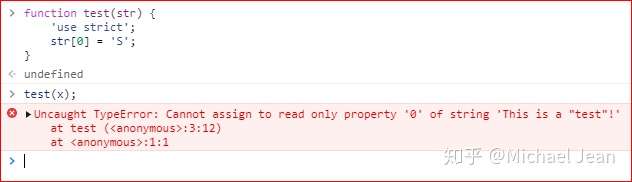
4 length属性
与数组相同,字符串也可以使用length看到成员的个数,并同样是只读属性:
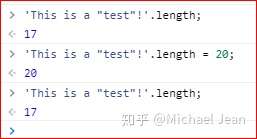
5 字符集
JavaScript 使用 Unicode 字符集。JavaScript 引擎内部,所有字符都用 Unicode 表示。
JavaScript 不仅以 Unicode 储存字符,还允许直接在程序中使用 Unicode 码点表示字符,即将字符写成\uxxxx的形式,其中xxxx代表该字符的 Unicode 码点。比如,\u00A9代表版权符号。
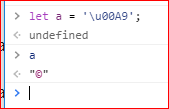
解析代码的时候,JavaScript 会自动识别一个字符是字面形式表示,还是 Unicode 形式表示。输出给用户的时候,所有字符都会转成字面形式。
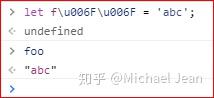
上面代码中,第一行的变量名foo是 Unicode 形式表示,第二行是字面形式表示。JavaScript 会自动识别。
我们还需要知道,每个字符在 JavaScript 内部都是以16位(即2个字节)的 UTF-16 格式储存。也就是说,JavaScript 的单位字符长度固定为16位长度,即2个字节。
但是,UTF-16 有两种长度:对于码点在U+0000到U+FFFF之间的字符,长度为16位(即2个字节);对于码点在U+10000到U+10FFFF之间的字符,长度为32位(即4个字节),而且前两个字节在0xD800到0xDBFF之间,后两个字节在0xDC00到0xDFFF之间。举例来说,码点U+1D306对应的字符为 ,它写成 UTF-16 就是0xD834 0xDF06。
JavaScript 对 UTF-16 的支持是不完整的,由于历史原因,只支持两字节的字符,不支持四字节的字符。这是因为 JavaScript 第一版发布的时候,Unicode 的码点只编到U+FFFF,因此两字节足够表示了。后来,Unicode 纳入的字符越来越多,出现了四字节的编码。但是,JavaScript 的标准此时已经定型了,统一将字符长度限制在两字节,导致无法识别四字节的字符。上一节的那个四字节字符 ,浏览器会正确识别这是一个字符,但是 JavaScript 无法识别,会认为这是两个字符。
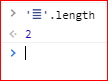
上面代码中,JavaScript 认为 的长度为2,而不是1。
总结一下,对于码点在U+10000到U+10FFFF之间的字符,JavaScript 总是认为它们是两个字符(length属性为2)。所以处理的时候,必须把这一点考虑在内,也就是说,JavaScript 返回的字符串长度可能是不正确的。
6 Base64转码
有时,文本里面包含一些不可打印的符号,比如 ASCII 码0到31的符号都无法打印出来,这时可以使用 Base64 编码,将它们转成可以打印的字符。另一个场景是,有时需要以文本格式传递二进制数据,那么也可以使用 Base64 编码。
所谓 Base64 就是一种编码方法,可以将任意值转成 0~9、A~Z、a-z、+和/这64个字符组成的可打印字符。使用它的主要目的,不是为了加密,而是为了不出现特殊字符,简化程序的处理。
JavaScript 原生提供两个 Base64 相关的方法。
- btoa():任意值转为 Base64 编码
- atob():Base64 编码转为原来的值
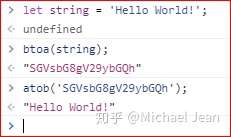
注意,这两个方法不适合非 ASCII 码的字符,会报错。

要将非 ASCII 码字符转为 Base64 编码,必须中间插入一个转码环节,再使用这两个方法。
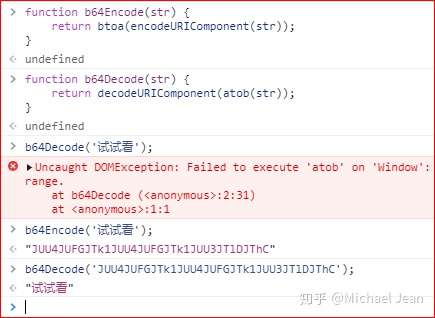
其中encodeURIComponent()以及decodeURIComponent()两个方法是用来对非ASCII字符进行转换的,这样可以保证得到的结果是可以由btoa()以及atob()识别的。
这里主要描述的是数据类型,故而一些针对字符串对象的方法,先略过,后文提及对应对象的时候,再详细解释,省的这文章太过复杂,毕竟是”从零开始“么。
评论
发表评论